…and also makes calculations!
In recent weeks, I worked primarily with the communication between Cantor and Scilab, via the backend that I am developing. The task was very interesting because in the project, the technology chosen for implementation, was changed.
Before, I had proposed to use the API call_scilab, which makes the communication between the C/C++ and Scilab. But, studying the code of Cantor, I realized that other backends uses KProcess class (or QProcess), which allows Qt code to initialize a thread of other software and make communication with him via the standard streams stdout, stderr and stdin.
However, Scilab originally did not use these streams. So, talking to my mentor Ledru, we decided to implement this functionality.
After a few days and further studies, could provide support to these outputs in Scilab! And, voilá, Scilab says “Hello Cantor!” via backend! Click images to enlarge:
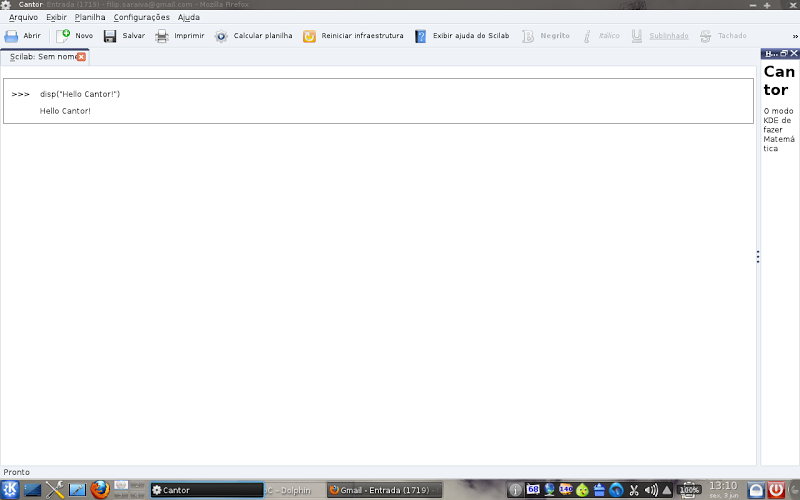
The backend is actually functional, although, of course, missing a few details. Now we have many screenshots. 🙂
Backend for Cantor Scilab making calculations:
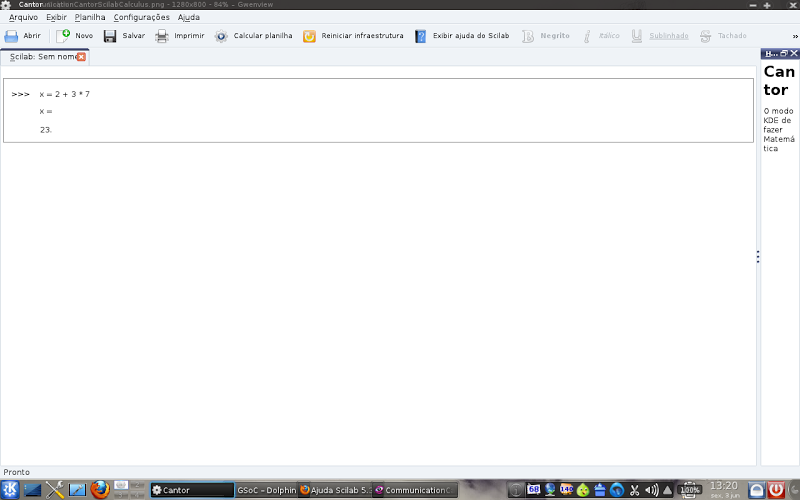
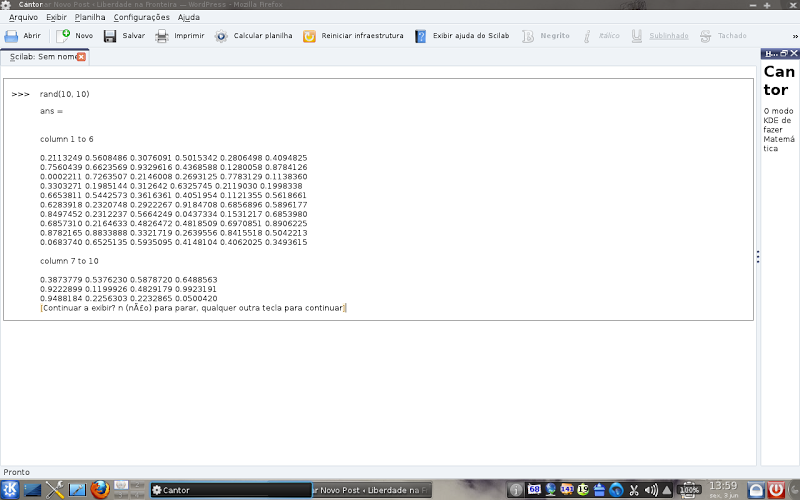
Add variables, uses pre-defined functions and allows various calculations in the same workspace:
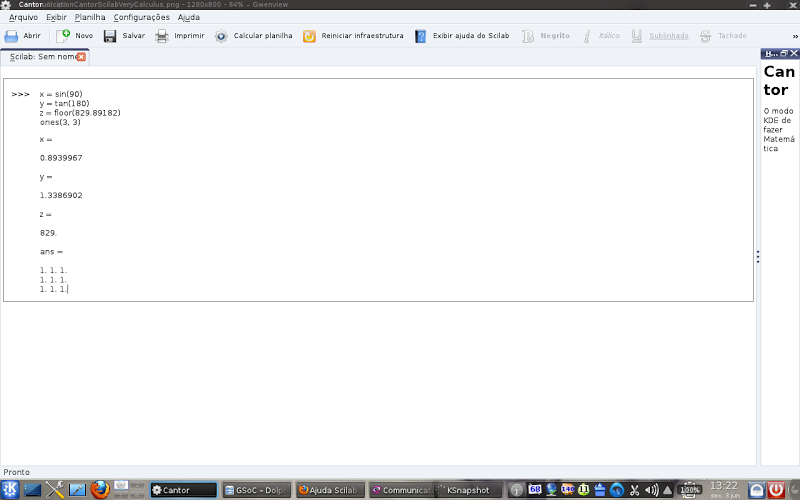
Works with multiple workspaces simultaneously:
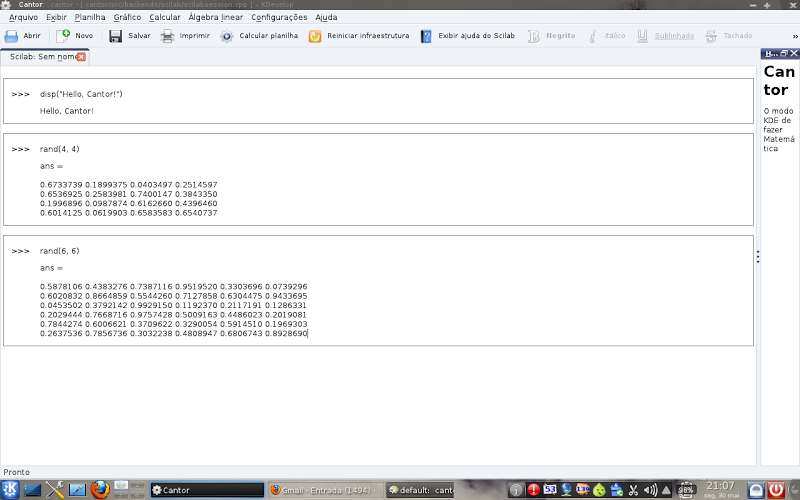
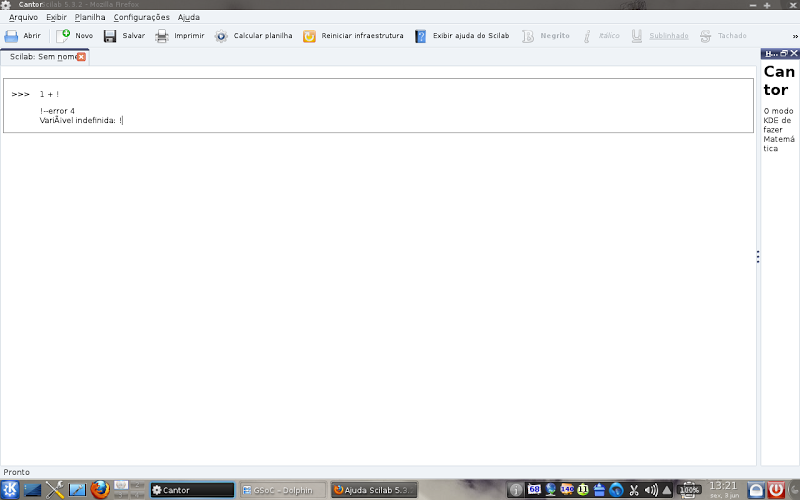
Emits error messages in the workspace:
That’s it! Well, let’s now a great resume with quick information about this project:
What’s missing?
- Management charting. Nowadays, the backend generates the chart of Scilab in another window. This will add the possibility of generating the chart in the workspace of the Cantor;
- Syntax highlighting;
- Auto-complete of the native Scilab functions;
- Working the character encoding of the output;
- Manage large outputs. When Scilab is a calculation and will print stuff on screen, the environment shows only a portion of the output and asks if the user wants to see more. In the backend it does not work, because when the first part of the output is shown, it is impossible to send another entry to Scilab. Below, in the image:
I can test this backend?
The backend code is in the branch scilab-backend Cantor repository, and performs all the functions described here. However, it needs the Scilab repository version to work, because I had to implement support for streams standards – ie, you must download the Scilab code and compile it. Another time, I’ll write a post with some tips on compiling Scilab.
For those who do not want to venture into the process of compiling Scilab, the way is to wait for the next version of Scilab to be launched in September. Just as it does in Scilab backend for Cantor function.
So that’s friends, who have to read the text here and stay tuned for more news. And do not forget to comment here about what you’re thinking of this project. 😉
Great news, and the project is definitely great too 🙂
But IMHO execution of interpreter using KProcess is just very ugly way to do things (especially when scilab provides such a simple API to execute code). This interactive shell wasn’t created to do such things (I mean working inside other project), in opposite to call_scilab. Moreover, scilab shell inside the cantor will simply eat more computer resourses (one more pipe, one more process, et cetera). Anyone can say “Who cares?”, and he’ll be right, because the difference in eaten resources will be minimal, but.. Well, if there’s correct and right way to do stuff and this way isn’t much harder to implement – why don’t just use it?
And BTW, clicking on image to see the larger version doesn’t work (I’m using Firefox 5.0 beta 2 if it is important).
Hello @User,
There aren’t “correct and right ways” to do this. There are choices. And what I did was follow the pattern of development of the other backends, do not demand a greater computational cost or even prohibitive.
To enlarge image, click with right button and select “View Image”. :p
Cheers.
Hi @Filipe Saraiva,
there isn’t really a “pattern of developement” in Cantor for talking to a backend(that’s why the whole backend code in the lib is so abstract). For example KAlgebra, R and the Qalculate(currently in playgroud) backends use some kind of API calls, while Sage,Maxima and Octave use the embedd-shell-approach. It is up to each backend to decide how to do things.
For sage and maxima the only reason I used that approach was they don’t seem to export any kind of API(that I’m aware of).
So please use whatever method is best for your backend. From my experience parsing the output is usually easier to set up at first, but it may lead to some weird and unexpected bugs. The API-way is normally the more failsafe way to go, but might be harder to set up initially (and there is the thing where you have to decide whether you want to directly access the API in cantors main process, in a separate thread, or in a separate process, see e.g. kalgebra vs. R backend).
I hope this comment sheds some light on why the current backends are implemented the way they are.
Anyway, keep up the good work,
best regards
Great job man! Thanks for sharing.
Best regards.
Thanks @Nelson!